On most servers you can use the button Turn On LED in the Storage Devices view so that you can identify which drives can be safely removed from the server easily. However if the drive is a NVMe SSD (as the ones shown below) this button might have no effect.
NVMe SSD drives
In this example an entire disk group (2 TB cache disk and three 8 TB capacity disks) shall be moved from an ESXi host in a vSAN cluster with spare capacity to a host belonging to a cluster where more datastore space is needed. The process is repeated for all hosts until the storage configuration is homogenous across all clusters, as per vSAN recommendations.
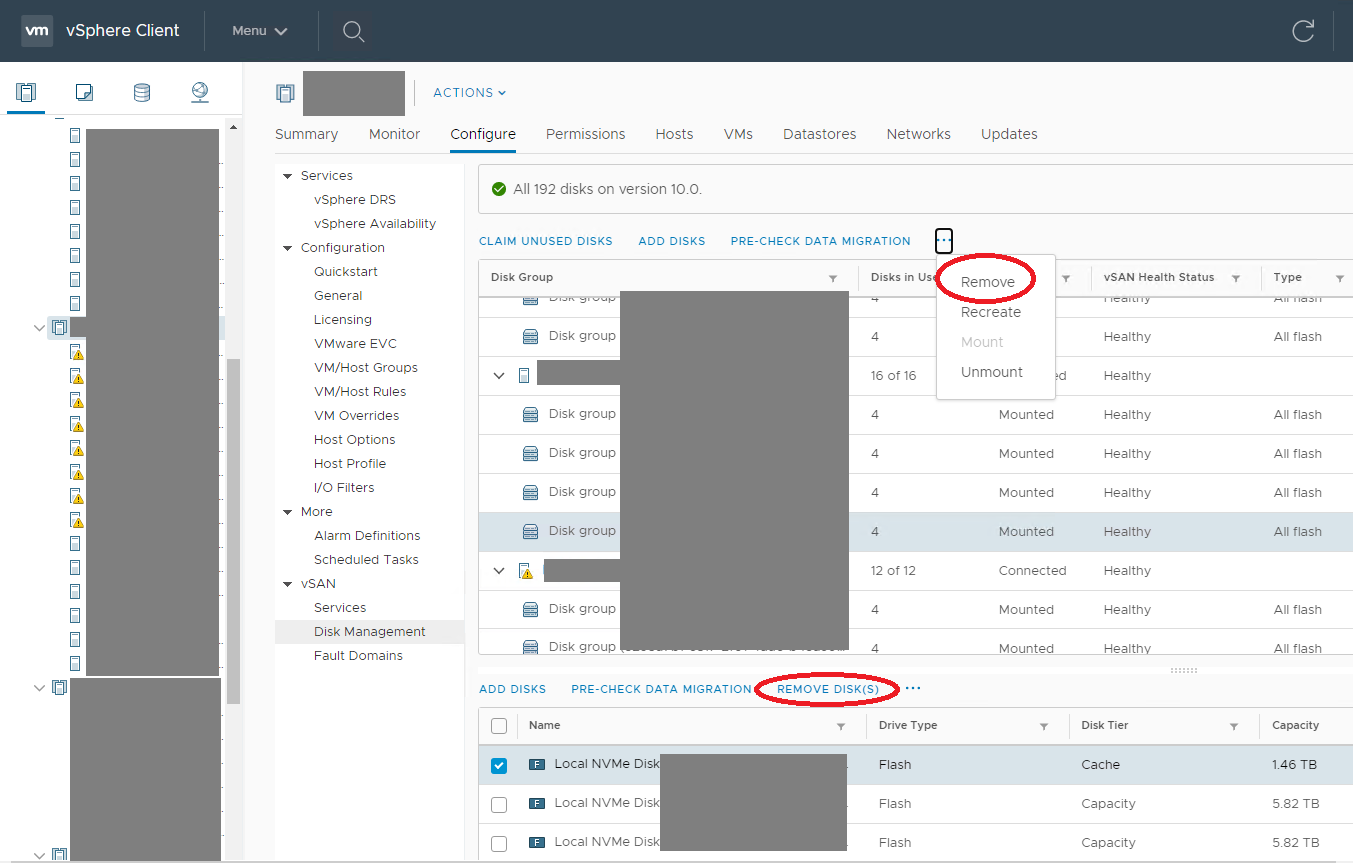
VMware vSphere Client – Remove vSAN disk / disk group
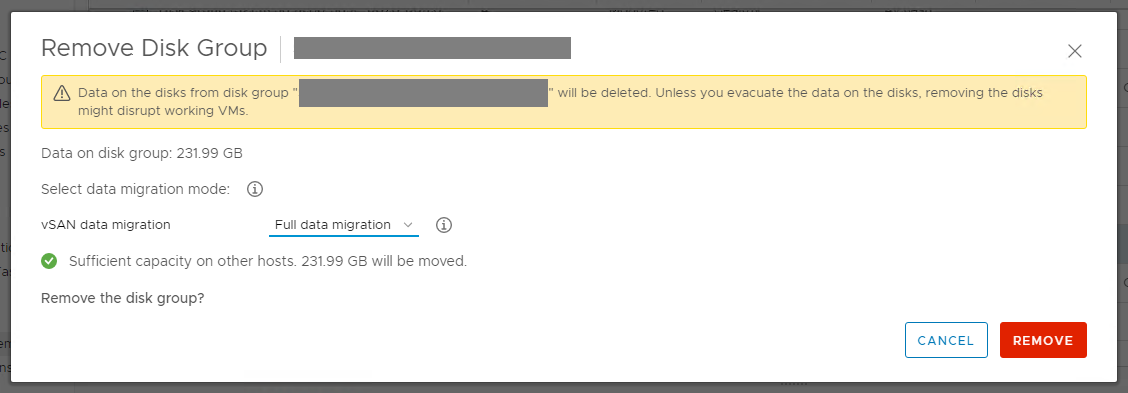
In case of the removal of an entire disk group the following window is displayed where the user must select an option for the vSAN data migration. Full data migration is recommended, as all the replicas for the configured Failures to tolerate policies are kept. Otherwise new replicas have to be re-created manually (Repair objects immediately button in the vSAN Skyline health view) or automatically after the repair delay time. This Object Repair Timer is set to 1 hour by default. So if a failure occurs in the components hosting the only remaining replica before the timer expires and the resync process is completed data loss may occur. The timer can be modified, but lower settings may lead to unwanted behavior, as explained in this KB article.
VMware vSphere Client – Remove vSAN disk group (Data migration)
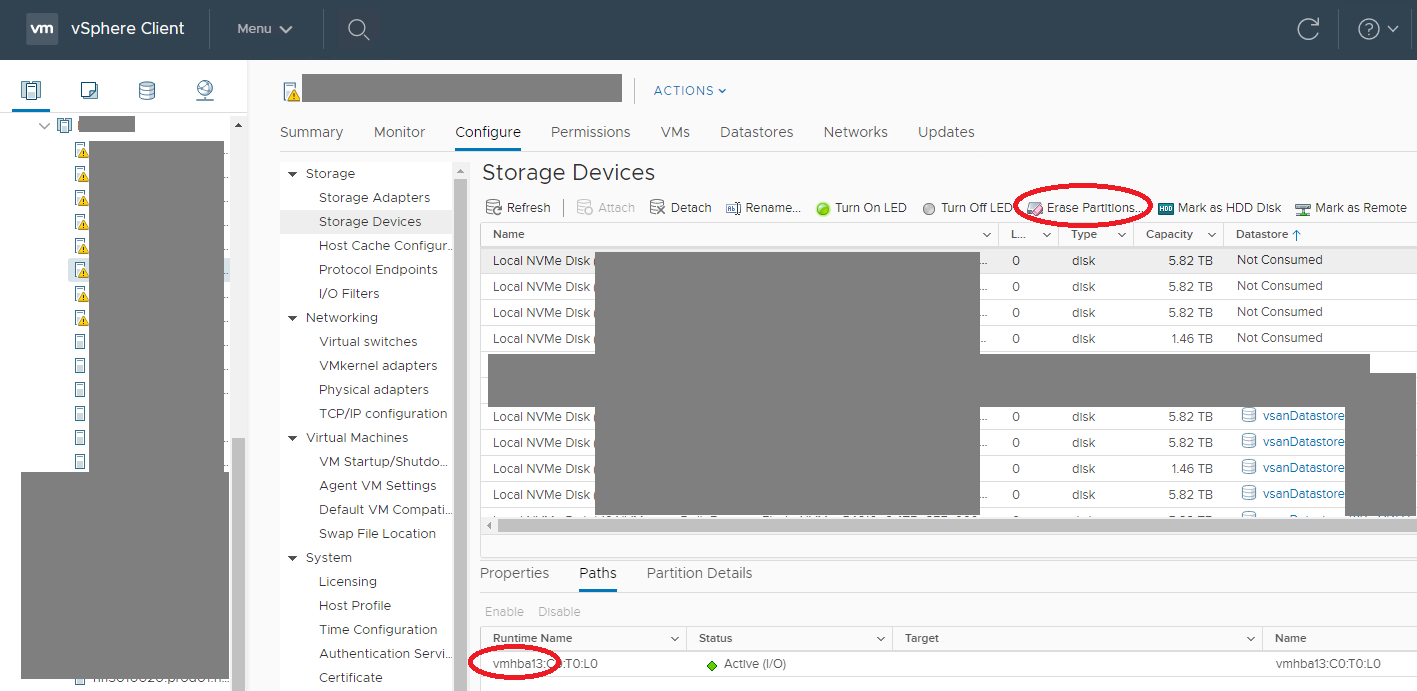
After the disks are removed from the cluster traces of vSAN partitions may remain on it, so I recommend to select the respective disks in the Storage Devices view and click on Erase Partitions as seen in below screenshot. If you forgot to do this and it fails (e.g. on a different server, where the disk has been relocated to, before erasing the partitions on the old one) check the instruction in my previous post. For identifying which bay the NVMe drive is located in you just removed and erased write down the vmhbaX number found in the Path view below.
VMware vSphere Client – Erasing partitions from storage device
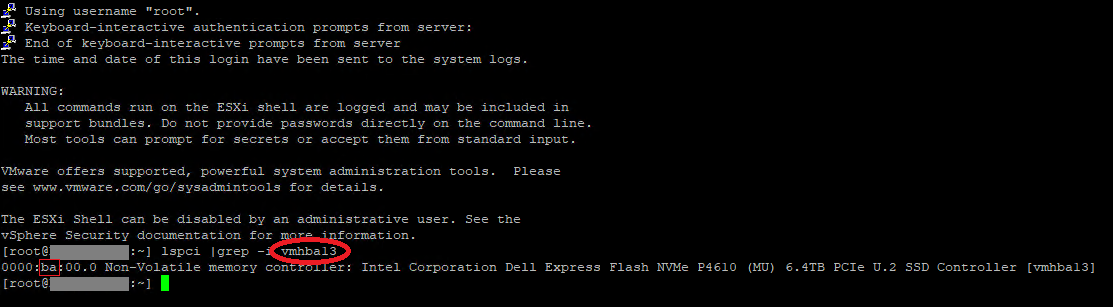
Now connect to the ESXi host via SSH and find the bus ID using the lspci command (filter using grep to narrow down the results):
VMware ESXi – Running lspci command in SSH session
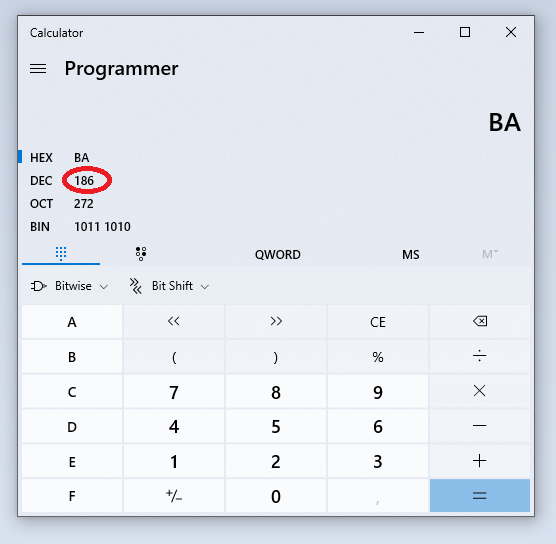
Convert the hexadecimal number after the four leading zeros to decimal representation using your favourite tool, e.g. programmer calculator:
Converting hex to decimal
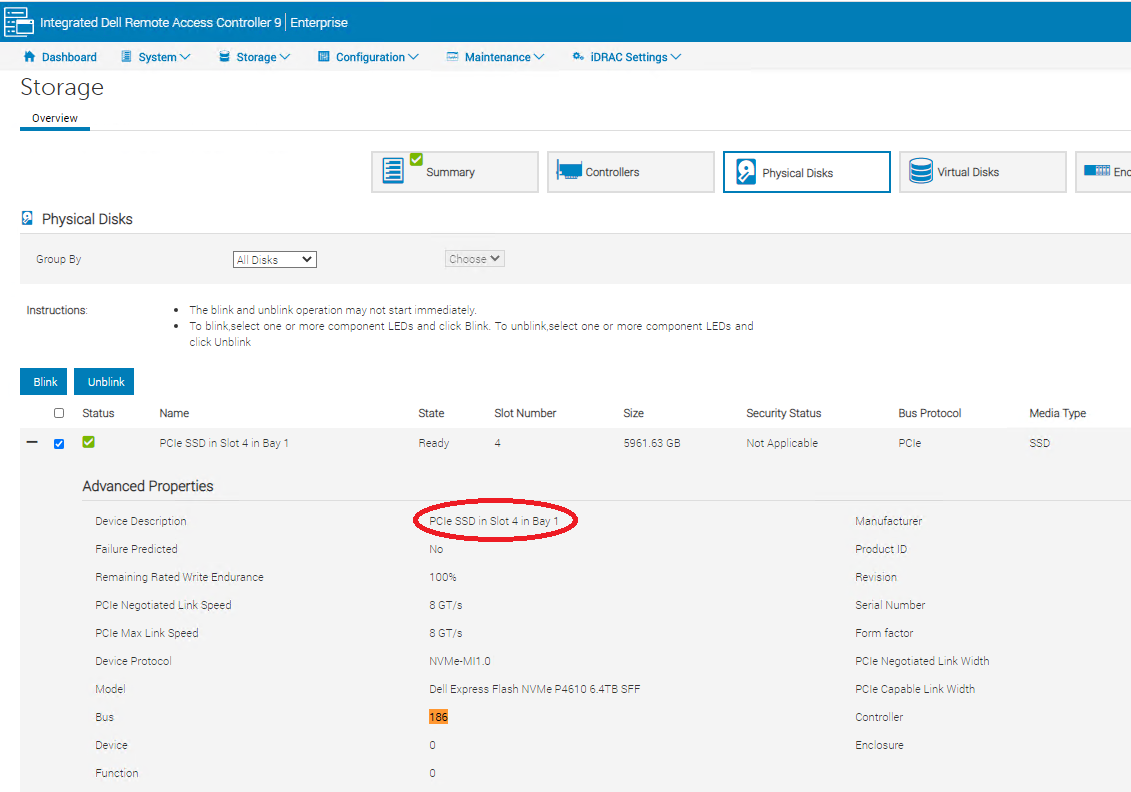
In the iDRAC web-interface of your Dell server open the System/Storage/Physical Disks view and find the disk with the bus ID number calculated above.
The string in the Device Description field gives a human readable representation of the drive�s position. Now you know which drive you removed from the vSAN cluster earlier and can safely remove it from the server:
Dell PowerEdge R740 Server with NVMe SSDs
More details, e.g. how to use the racadm CLI tool instead of the iDRAC web-interface, can be found in this KB article by Dell.
In VMware Cloud Foundation (VCF) workloads usually are deployed in one or more dedicated virtual infrastructure (VI) workload domains. During the VCF deployment (as shown in my earlier posts) the management workload domain (MWLD) is created with a minimum of four hosts. The WLD contains among other components the management vCenter and the SDDC manager. For each VI workload domain (WLD) created using the SDDC manager a separate vCenter is deployed in the MWLD. The vCenters manage the WLD�s hosts and use the vSphere linked mode. As only fifteen vCenters can be linked as per current configuration maximums, currently up to 14 WLDs are supported. Before the SDDC manager can create a WLD enough hosts (minimum three per WLD) need to be commissioned. Click on the button “Commission hosts” either in the Dashboard or the Inventory/Hosts view:
VMware Cloud Foundation – SDDC Manager, Commission hosts
The hosts need be be prepared similarly to the VCF deployment. This includes ESXi version, hardware configuration and network settings (e.g. DNS resolution) and shown in below checklist. In a later post I will provide some helpful PowerCLI snippets to accelerate the host preparation.
VMware Cloud Foundation – SDDC Manager, Commission hosts, Checklist
After clicking on “Proceed” the details of the hosts need to be provided. Either add each individual host manually (Select “Add new”) or perform a bulk commission by preparing and uploading a JSON file:
VMware Cloud Foundation – SDDC Manager, Commission hosts, host addition
The JSON template provided looks like this:
{
"hostsSpec": [
{
"hostfqdn": "Fully qual. domain name goes here",
"username": "User Name goes here",
"storageType": "VSAN/NFS",
"password": "Password goes here",
"networkPoolName": "Network Pool Name goes here"
},
{
"hostfqdn": "Fully qual. domain name goes here",
"username": "User Name goes here",
"storageType": "VSAN/NFS",
"password": "Password goes here",
"networkPoolName": "Network Pool Name goes here"
}
]
}
Not only the host�s details (FQDN, credentials) and the storage type (preferably vSAN) needs to be provided, but the network pool to be used. Later on also license keys are required. A total of three license keys for vSphere, vSAN and NSX should be entered in the “Administration/License” screen of the SDDC manager. Network pools are created in the “Administration/Network settings” screen. In this case VLAN-IDs and subnet for vMotion and vSAN separate from the default pool (used by the MWLD) are used:
VMware Cloud Foundation – SDDC Manager, Network pools
After the hosts are commissioned they show up in the “Usassigned hosts” tab:
VMware Cloud Foundation – SDDC Manager, Inventory/Hosts
Click on a host to show its details, e.g. manufacturer, model and storage capacity:
VMware Cloud Foundation – SDDC Manager, Inventory/Hosts, Host details
To create a new WLD use the “+ workload domain” button in the inventory:
VMware Cloud Foundation – SDDC Manager, Workload Domains
Select your storage in the next dialog box. vSAN and NFS are fully supported out of the box (Fibre Channel can be added later on manually, but must be managed independently):
VMware Cloud Foundation – SDDC Manager, Workload Domains, Add VI WLD, Step 0
In the first step of the VI configuration wizard enter names for the WLD, the first cluster and the organization the domain is intended for:
VMware Cloud Foundation – SDDC Manager, Workload Domains, Add VI WLD, Step 1
Then enter a free IP address in the management subnet, a FQDN configured in your DNS servers and root password for the WLD�s vCenter:
VMware Cloud Foundation – SDDC Manager, Workload Domains, Add VI WLD, Step 2
The most interesting part if you are enthusiastic for VMware�s SDN portfolio is the networking screen, which allows you to choose between the legacy product NSX-V or the 2019 released NSX-T version 2.4. In both cases FQDNs, IP addresses and root/admin password for the NSX managers must be entered, as well as a VLAN ID used for the overlay transport (VXLAN for NSX-V; Geneve for NSX-T):
VMware Cloud Foundation – SDDC Manager, Workload Domains, Add VI WLD, Step 3
If you selected vSAN as primary storage provider in the first step you need to enter the PFTT (primary failure to tolerate) parameter in step four. “One failure to tolerate” means each data set is replicated once, similar to RAID 1. This means that any of the three required hosts can fail at any point in time without data loss. If you have at least five hosts you can select PFTT=2, which means data is replicated twice, so two hosts may fail simultaneously. This is only the default setting however. PFTT can be set for each object via storage profiles later on, too.
VMware Cloud Foundation – SDDC Manager, Workload Domains, Add VI WLD, Step 4
In the next steps select the hosts which shall be used for initial WLD creation. Further hosts can be added to the WLD later. The host selection screen previews the accumulated resources of the selected hosts:
VMware Cloud Foundation – SDDC Manager, Workload Domains, Add VI WLD, Step 5
In the License step select the license keys entered before from the drop down menus. Each license should provide enough capacity for each product (e.g. enough CPU socket count) and not be expired:
VMware Cloud Foundation – SDDC Manager, Workload Domains, Add VI WLD, Step 6
The last two screens show a review of all entered parameters and a preview of the component names which will be created:
VMware Cloud Foundation – SDDC Manager, Workload Domains, Add VI WLD, Step 7VMware Cloud Foundation – SDDC Manager, Workload Domains, Add VI WLD, Step 8
After finishing the wizard the creation progress can be tracked in the Tasks view in the bottom of the SDDC manager. If you click on the task all of its subtasks and their status are shown below:
VMware Cloud Foundation – SDDC Manager, Workload Domains, Add VI WLD, Subtasks 1VMware Cloud Foundation – SDDC Manager, Workload Domains, Add VI WLD, Subtasks 2
After some time the WLD creation tasks should succeed:
VMware Cloud Foundation – SDDC Manager, Workload Domains, Creating VI WLD succeeded
Open the overview of the newly created WLD under the “Inventory/Workload Domains” to show its status. The “Services” tab features links to the vCenter and the NSX-T manager GUIs:
VMware Cloud Foundation – SDDC Manager, Workload Domains, Details of WLD
After a host is removed from a workload domain or the entire WLD is deleted the hosts are found under the tab “Unassigned hosts” again, but their state shows “Need Cleanup”:
VMware Cloud Foundation – SDDC Manager, Inventory/Hosts, Decommissioning
First select the checkbox on the left of each host needing cleanup and click on the button “Decommission selected hosts”.
Then login into the SDDC manager using SSH (e.g. “ssh [email protected]”) and prepare a JSON file containing the hosts and their management credentials as follows:
Now run the following commands found in the VCF documentation to commence the cleanup:
su
cd /opt/vmware/sddc-support
./sos --cleanup-decommissioned-host /tmp/dirty_hosts.json
VMware Cloud Foundation – SDDC Manager, Host cleanup script
Afterwards however there is still the task of the network cleanup, which requires access to Direct Console User Interface (DCUI). If the network cleanup is not performed you will be presented with errors as shown below when trying to re-commission the hosts:
VMware Cloud Foundation – SDDC Manager, Host addition of partly cleaned up hosts, Error 1VMware Cloud Foundation – SDDC Manager, Host addition of partly cleaned up hosts, Error 2
When logging into the ESXi management GUI in your browser you can see the left over distributed virtual switch and its port groups from the previous WLD:
VMware ESXi, Network settings
Perform the network cleanup by logging into the DCUI with the root user and then select “Network Restore Options”:
VMware ESXi, DCUI, Network Restore Options
Then select “Restore Network Settings” option which resets any network settings and devices to the defaults:
Re-configuration of management network settings like IP address, subnet mask, default gateway and VLAN is needed afterwards. Now of the cleaned hosts are ready to be re-commissioned, which works as shown in the beginning of this post.
When a VMware Cloud Foundation deployment was updated to the current version, as described previously, a few tasks should be done afterwards. First the vSAN datastore disk format version might need an upgrade. To check this head to the “Configure” tab of your DC in vCenter and click on “vSAN /Disk Management”:
vCenter cluster overview after VMware Cloud Foundation Update 3.5
Of course you should run the pre-check by clicking on the right button. If everything is working as it should it would look like this:
vCenter cluster overview after VMware Cloud Foundation Update 3.5�(vSAN upgrade�pre-check)
Now you can click the “Upgrade” button, which informs you this can take a while. Also you should backup your data/VMs elsewhere, especially if you select “Allow Reduced Redundancy”, which speeds up the process:
vCenter cluster overview after VMware Cloud Foundation Update 3.5�(vSAN upgrade)
As you can see now the disk format version has changed from “5” to “7”:
vCenter cluster overview after VMware Cloud Foundation Update 3.5�(vSAN upgraded)
However still some vSAN issues are displayed:
vCenter cluster overview after VMware Cloud Foundation Update 3.5�(vSAN issues)
As this deployment is a “dark site”, meaning no internet access is available, the HCL database and Release catalog have to be updated manually.
vCenter cluster overview after VMware Cloud Foundation Update 3.5�(vSAN Update)
The URL to download the 14.7 MB file can be found in a post from William Lam from 2015 or in this KB article. The release catalog�s URL is taken from another KB article. This file is less than 8 KB in size. After uploading both using the corresponding “Update from file” buttons the screen should look like this:
vCenter cluster overview after VMware Cloud Foundation Update 3.5�(vSAN updated)
The last remaining issue in this case was the firmware version of the host bus adapter connecting the vSAN datastore devices could not be retrieved (“N/A”):
vCenter cluster overview after VMware Cloud Foundation Update 3.5�(vSAN Health)
Since the firmware version listed in the hosts iDRAC (see next screenshot) matches one of the “Recommended firmwares” from above I decided to rather hit “Silence alert”. Eventually one could look for an updated VIB file allowing the ESXi host to retrieve the firmware version from the controller.
iDRAC overview of storage controllers
One more effect of the upgrade from 3.0.1.1 to 3.5 is the appearance of three more VMs in vCenter. These are the old (6.5.x) instances of the platform service controllers and the vCenter. New instances with version 6.7.x have been deployed during the upgrade. After all settings had been imported from the old ones, these were apparently powered off and kept in case something would have gone wrong. After a period of time and confirming everything works as expected those three VMs may be deleted from the datastore:
vCenter VM overview�showing�old�PSCs�and�vCenter�instances
Sometimes when a storage device (i.e. SSD or HDD) has been used for a previous vSAN deployment or has other leftovers it cannot be re-used (either for vSAN or a local VMFS datastore) right away. When you try to format the drive as shown below the error message “Cannot change the host configuration”:
Erase paritions highlighted in the Storage Devices view of a ESXi host in vSphere Client 6.7U1
The easiest way is to change the partition scheme from GPT to MSDOS via CLI (and back via GUI) and has been described in the community before.
However, even that may fail, e.g. because of the error “Read-only file system during write”. This can occur if the ESXi hypervisor finds traces of old vSAN deployments on the drive and refuses to overwrite these. In that case you first have to delete those traces manually. Log into the host in question as the root user and issue the vSAN commands needed. These are the commands for listing all known vSAN disks, deleting a SSD (cache device) and a (capacity) disk: